


Video Game Generation: A Practical Study using Mario


We present MarioVGG, a text-to-video diffusion model for controllable video generation on the Super Mario Bros game. MarioVGG demonstrates the ability to continuously generate consistent and meaningful scenes and levels, as well as simulate the physics and movements of a controllable player all through video.
To read the full paper, click here.
Abstract
This work reports the study of video generative models for interactive video game generation and simulation. We discuss and explore the use of available pre-trained open-sourced video generation models to create playable interactive video games. While being able to generate short clips of broad range of described scenes, such models still lack controllability and continuity. Given these limitations, we focus on producing and demonstrating a reliable and controllable video game generator on a single game domain. We present MarioVGG, a text-to-video diffusion model for controllable video generation on the Super Mario Bros game. MarioVGG demonstrates the ability to continously generate consistent and meaningful scenes and levels, as well as simulate the physics and movements of a controllable player all through video.
Overview
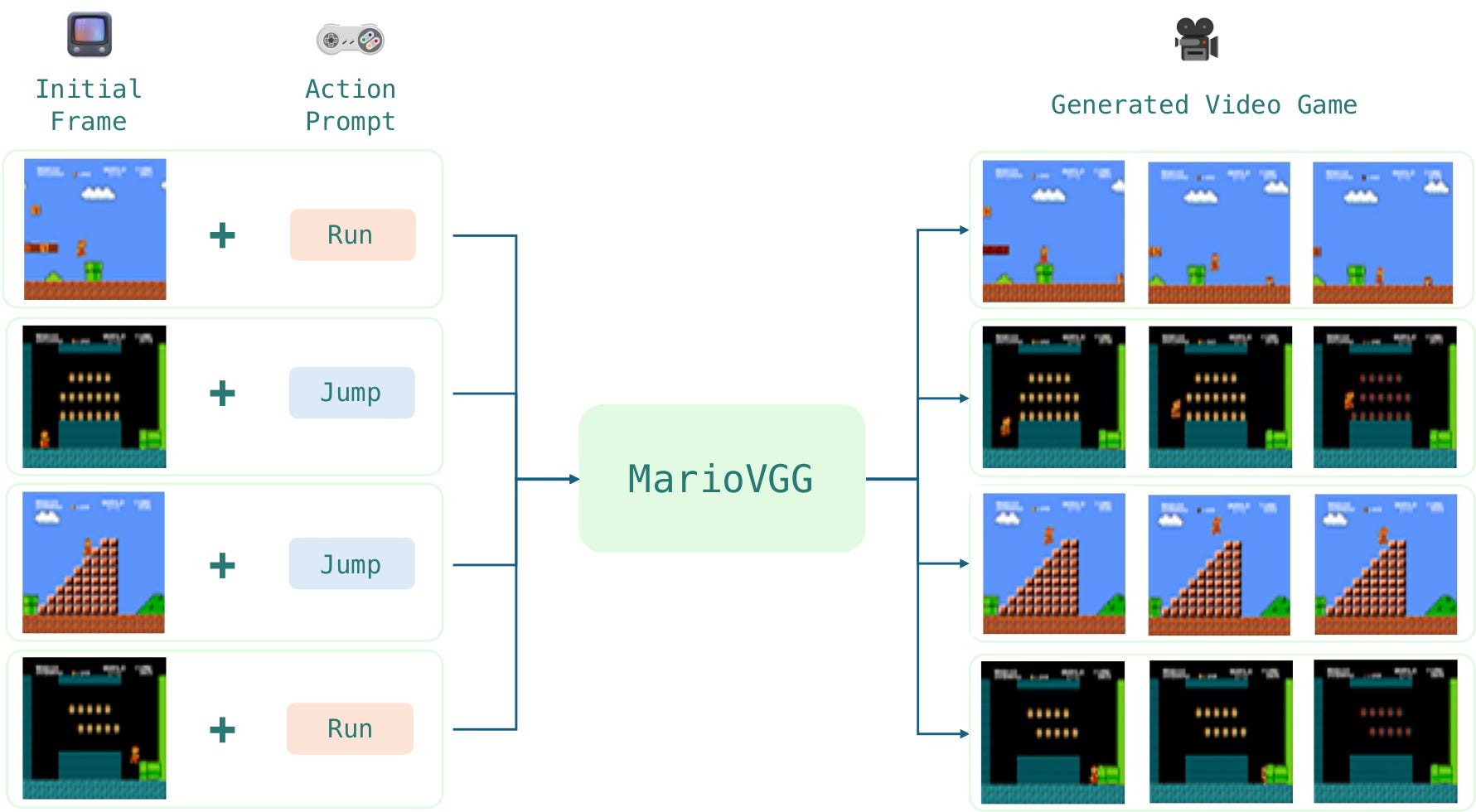
MarioVGG is a text-to-video model which takes in the initial game state as a single image frame, and an action in the form of a text prompt. It then outputs a video (a sequence of frames) depicting the action in the game.

To generate and maintain gameplay for longer horizons, we chain together multiple model generations recursively.
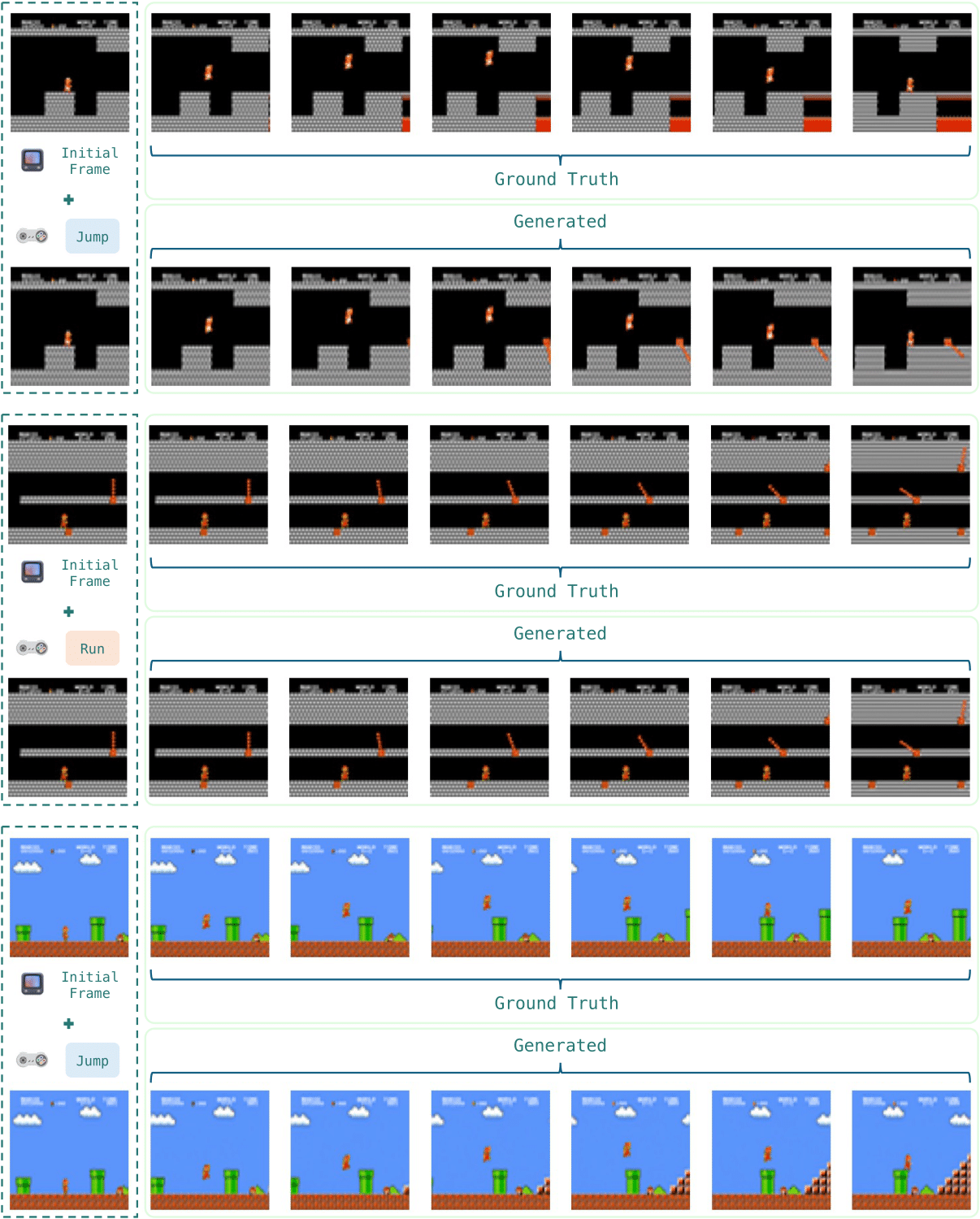
Comparison between MarioVGG-generated frames and ground truth frames.
MarioVGG Gameplay Examples
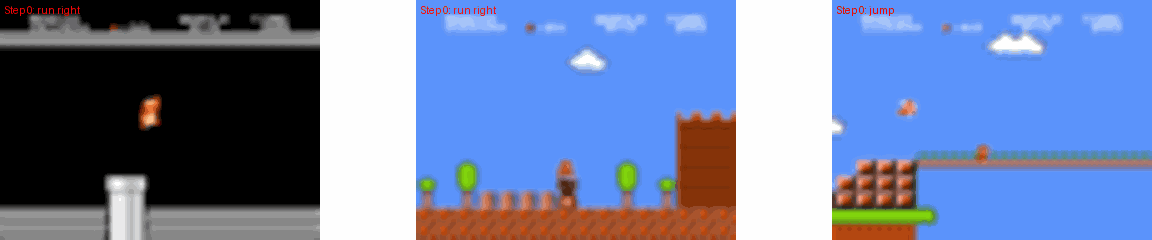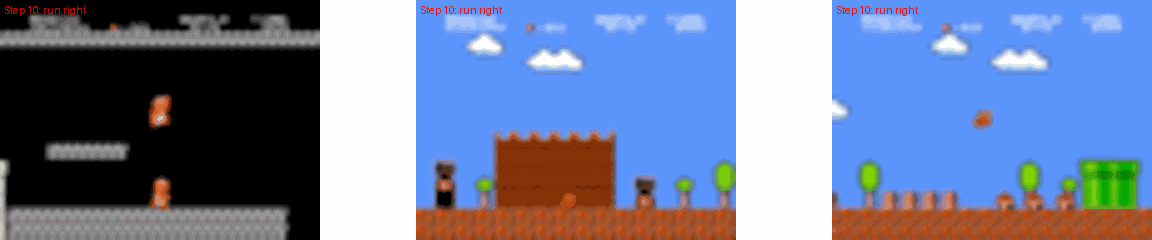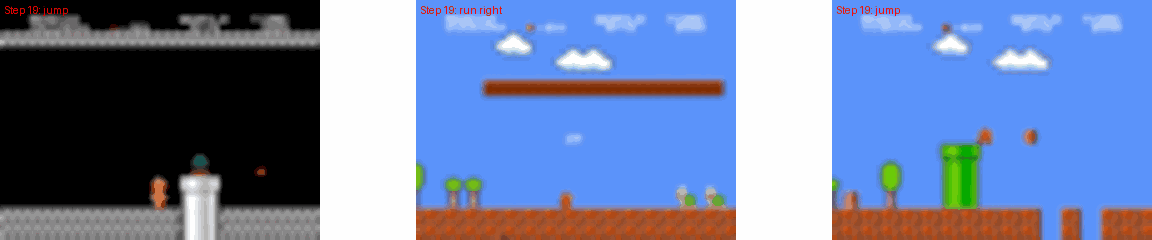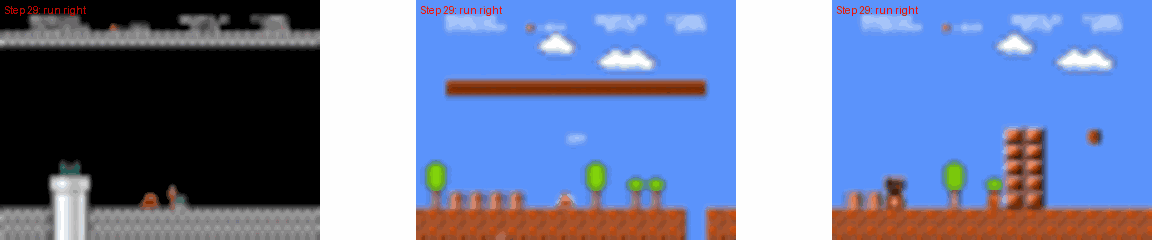


太牛逼了!